Research
Image Stitching and Super-resolution | Image Forensics | Aids for Visually Impaired People
Visual Odometry and SLAM
Stereo visual odometry with accurate frame selection
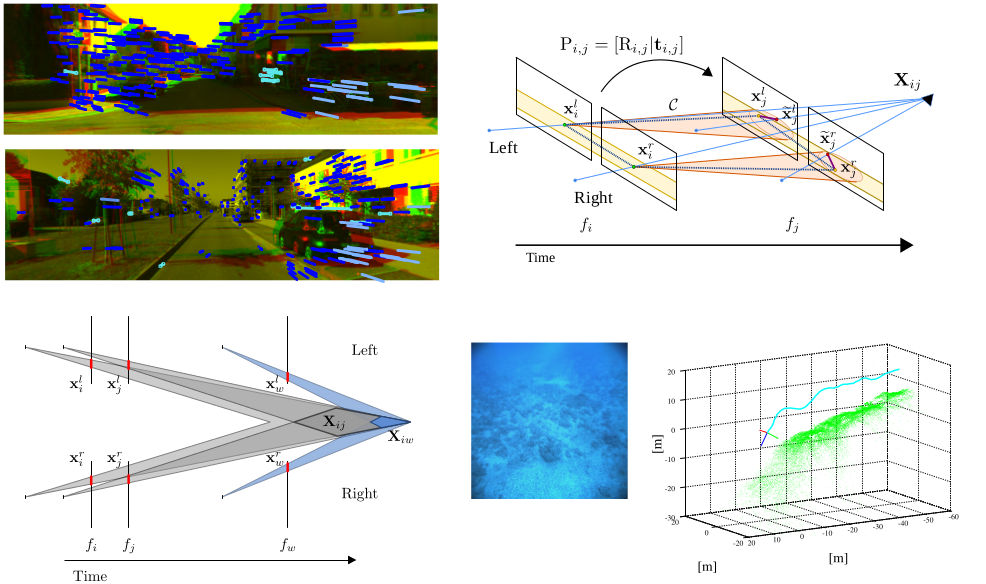
SSLAM (Selective SLAM) is a novel stereo visual odometry (VO) framework based on Structure from Motion, where robust keypoint tracking and matching are combined into an effective keyframe selection strategy. The main aspect characterizing SSLAM is the careful selection of the keyframes used as references for camera trajectory computation. Keyframes are selected only if a strong temporal feature disparity is detected. This idea arises from the observation that localization uncertainty of 3D points is higher for distant points characterized by small temporal image disparity. The proposed strategy can be more stable and effective with respect to using a threshold on the average temporal disparity or a constant keyframe interleaving. Additionally, a robust loop chain matching scheme is used, improving upon VISO2-S by using a more robust detector-descriptor pair, to find correspondences also in images with large spatial and/or temporal disparity as the requested keyframes. The proposed solution is effective and robust even for very long paths, and has been used as support to AUV navigation in real complex underwater environments.
SAMSLAM: Simulated Annealing Monocular SLAM
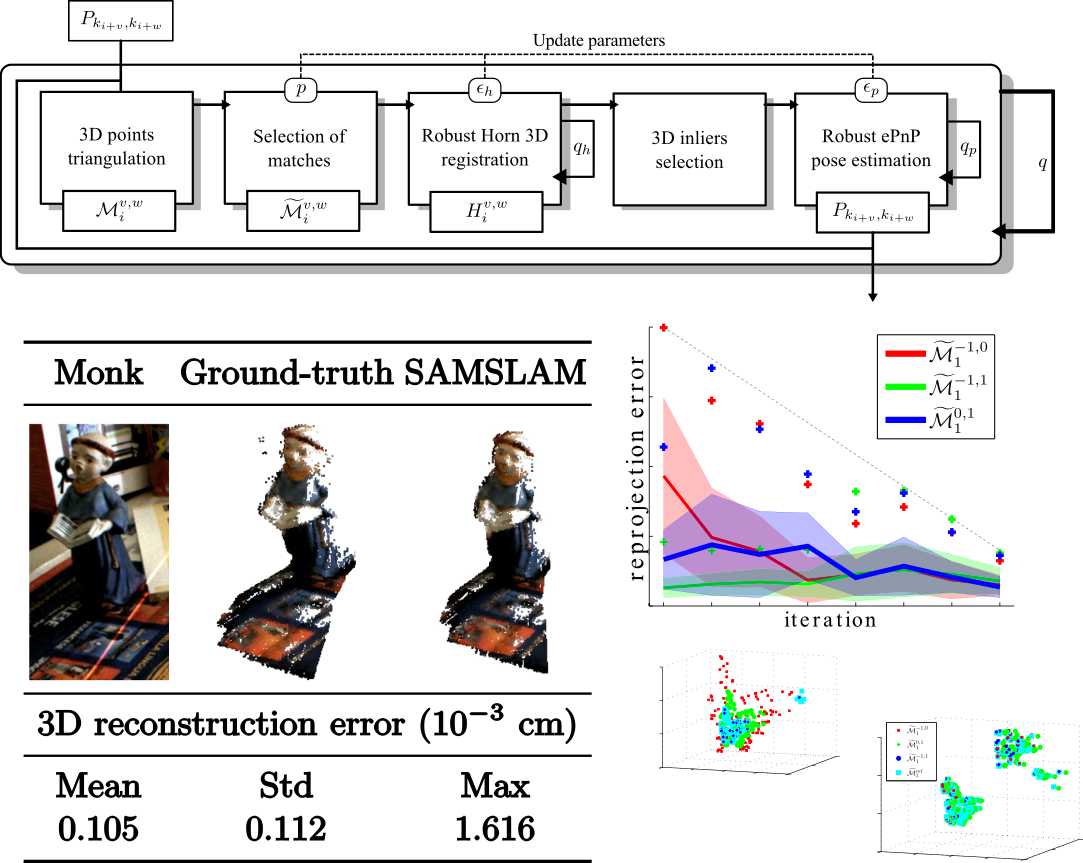
SAMSLAM (Simulated Annealing Monocular SLAM) replaces the classic global Structure from Motion optimized approach - for obtaning both the 3D map and the camera pose - with a robust simulated annealing scheme. It works locally on triplets of successive overlapping keyframes, thus guaranteeing scale and 3D structure consistency. Each iterative step uses RANSAC and alternates between the registration of the three 3D maps associated to each image pair in the triplet and the refinement of the corresponding poses, by progressively limiting the allowable reprojection error. SAMSLAM does not require neither global optimization nor loop closure. Moreover, it does not perform any back-correction of the poses and does not suffer of 3D map growth.
Fast keyframe selection for Visual SfM using DWAFS
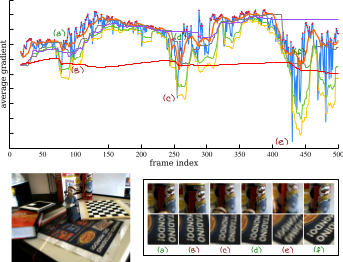
DWAFS (Double Window Adaptive Frame Selection) is a new fast online preprocessing strategy to detect and discard ongoing bad frames (too blurry or without relevant content changes) in video sequences. Unlike keyframe selectors and deblurring methods, the proposed approach does not require complex time-consuming image processing, such as the computation of image feature keypoints, previous poses and 3D structure. The method can be used to directly filter a Structure from Motion video input improving the final 3D reconstruction by discarding noisy and non-relevant frames, also decreasing the total computation cost. DWAFS is based on the gradient percentile statistics of the input frames, where an adaptive decision strategy - based on a dangling sampling window based on the ongoing values and the last best ones - is used.
3D Reconstruction
3D Map Computation from Historical Stereo Photographs of Florence

This work deals with the analysis of historical photos with the final objective of reconstruct in 3D the old structures so to facilitate its comparison with the scene at the present time. In particular we use the stereograms of Anton Hautmann - one of the most active photographers working in Florence in the middle of the 19th century. This work has been carried out within the project TRAVIS (Tecniche di Realtà Aumentata per la Visualizzazione di Immagini Storiche), funded by Ente Cassa di Risparmio di Firenze (bando Giovani Ricercatori Protagonisti, 2015)
2D to 3D semi-automatic image conversion for stereoscopic displays
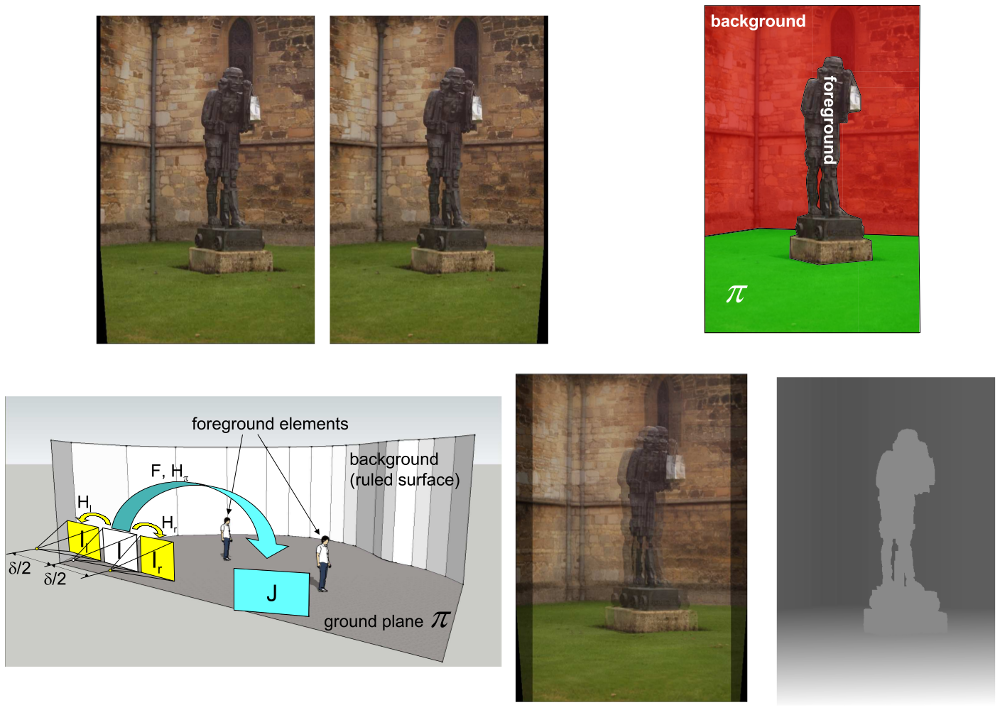
This project describes the development of a fast and effective 2D to 3D conversion scheme to render 2D images on stereoscopic displays. The stereo disparities of all scene elements (including background and foreground) are computed after statistical segmentation and geometric localization of the ground plane. An original algorithm is devised for recovering 3D visual parameters from planar homologies. The theatrical model employed for the scene provides a effective 3D impression of the displayed scene, and it is fast enough to process video sequences.
3D change detection

Tracking the structural evolution of a site has important fields of application, ranging from documenting the excavation progress during an archaeological campaign, to hydro-geological monitoring. We developed a simple yet effective method that exploits vision-based reconstructed 3D models of a time-changing environment to automatically detect any geometric changes in it. Changes are localized by direct comparison of time-separated 3D point clouds according to a majority voting scheme based on three criteria that compare density, shape and distribution of 3D points.
LaserGun: Hybrid 3D reconstruction combining visual odometry and laser scanning
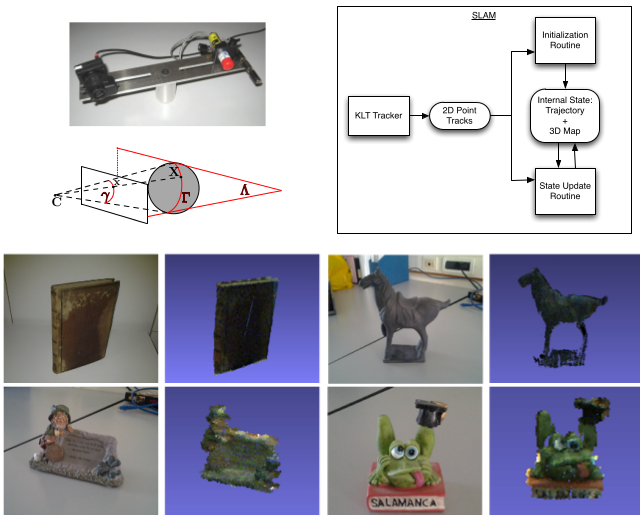
LaserGun combines visual odometry techniques with active laser scanning triangulation. After the initial calibration of the relative elements of the system (i.e the camera intrinsic calibration parameters and the laser plane), laser profiles are employed to extract object 3D structure while visual odometry information is used to track and merge the data from the video frames. According to the experimental results, greater accuracy is achieved by the system when planar homography decomposition is used to track the camera instead of using a monocular SLAM approach.
MagicBox: Photometric stereo for accurate leather fabric reproduction

MagicBox is a hardware/software system designed for the accurate acquisition of 3D surfaces using photometric stereo and employed to get high-quality digitalized reproductions of leather fabric samples. MagicBox combines a hardware module that controls the acquisition environment needed to illuminate the input object from different lighting directions with a computer vision module that assembles the final virtual fabric result.
Local Image Descriptors
Robust keypoint matching with sGLOH-based descriptors

The sGLOH descriptor is able to handle discrete rotations of the keypoint patch by a simple permutation of its vector components.-sGLOH can be used in combination with a global or a priori orientation estimation to filter keypoint correspondences, thus improving the matches. sGLOH2 extends the descriptor by concatenating two sGLOH descriptor for the same patch with a relative rotation offset, improving the original robustness and discriminability when in-the-middle rotations occour. Still, an adaptive, general, fast matching scheme can be used to significantly reducing both computation time and memory usage, while binarization based on comparisons inside each descriptor histogram yields the more compact, faster, yet robust, alternative BisGLOH2. sGLOH-based descriptors come with an exhaustive comparative experimental evaluation on both image matching and object recognition. According to this evaluation the proposed descriptors achieve state-of-the-art results.
-
F. Bellavia and C. Colombo, "Rethinking the sGLOH descriptor", TPAMI, 2018 | PDF | Additional material
Evaluation of recent local image descriptors for image matching
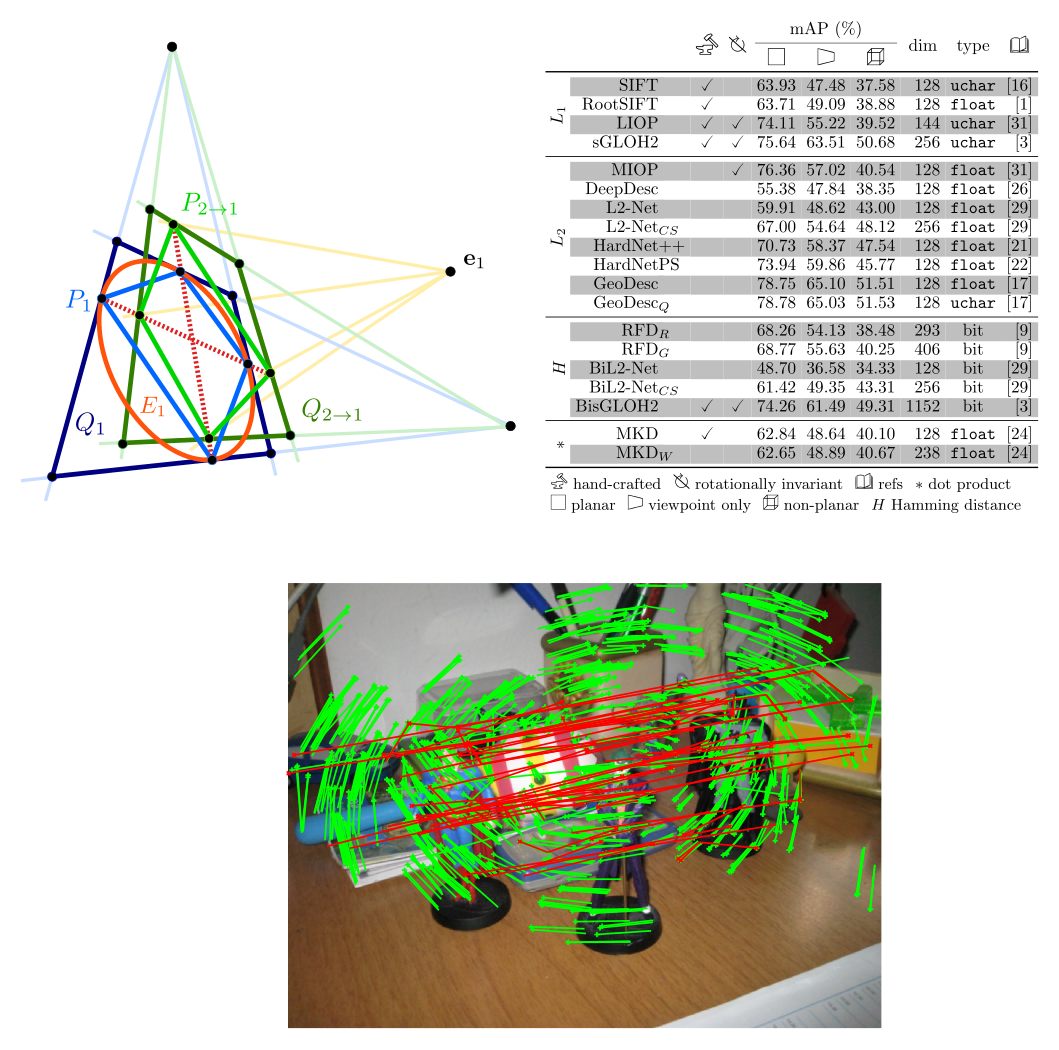
A comparison of the best and most recent local image descriptors on planar and non-planar scenes under viewpoint changes is presented. This evaluation, aimed at assessing descriptor suitability for real-world applications, leverages the concept of Approximated Overlap error as a means to naturally extend to non-planar scenes the standard metric used for planar scenes. According to the evaluation results, most descriptors exhibit a gradual performance degradation in the transition from planar to non-planar scenes. The best descriptors are those capable of capturing well not only the local image context, but also the global scene structure. Deep learned descriptor approaches are shown to have reached the matching robustness and accuracy of the best handcrafted descriptors.
Which is Which? Evaluation of local descriptors for image matching in real-world scenarios

This paper presented the results of the WISW contest, held at the CAIP 2019 conference, aimed at benchmarking recent local descriptors in challenging real image matching scenarios on both planar and non-planar scenes. The WISW contest extended existing datasets by adding more test images. In the case of planar scenes, viewpoints changes were combined with other image transformations to achieve a more realistic and challenging complexity. On planar evaluation, WISW follows the HPatches protocol, but also custom patch orientations are allowed. For non-planar scenes, the benchmark is based on a piecewise approximation of the overlap error. Evaluation showed remarkable improvements of recent descriptors, particularly impressive for deep descriptors, thanks to their smart architecture, combined to the ever increasing availability of big data and modern hardware capabilities. The proposed benchmark evidenced the fact that, beside descriptors, other factors often overlooked, such as patch orientation assignment and matching strategy, are critical for image matching.
-
F. Bellavia and C. Colombo, "Which is Which? Evaluation of local descriptors for image matching in real-world scenarios", CAIP, 2019 | PDF | Website | Source code | Dataset
Is there anything new to say about SIFT matching?

SIFT is a classical hand-crafted, histogram-based descriptor that has deeply influenced research on image matching for more than a decade. A critical review of the aspects that affect SIFT matching performance is carried out, and novel descriptor design strategies are introduced and individually evaluated. These encompass quantization, binarization, Manhattan vs Euclidean distance, and hierarchical cascade filtering as means to reduce data storage and increase matching efficiency, with no significant loss of accuracy. An original contextual matching strategy based on a symmetrical variant of the usual nearest-neighbor ratio is discussed as well, that can increase the discriminative power of any descriptor. A comprehensive experimental evaluation of state-of-the-art hand-crafted and data-driven descriptors, also including the most recent deep descriptors, is finally carried out on both planar and non-planar scenes.
Image Stitching and Super-resolution
Best reference homography estimation for planar mosaicing
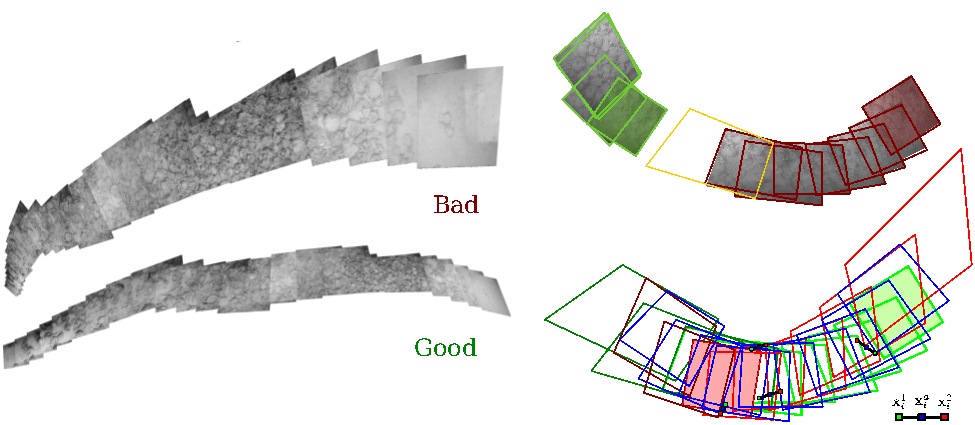
A mosaicing pipeline is developed to globally reduce the distortion induced by a wrong viewpoint selection given by a bad choice of the mosaic reference homography. In particular, the input sequence is split into almost planar sub-mosaics that are then merged hierarchically by a bottom-up approach according to their overlap error when reprojected through the "average homography". Given two sub-mosaics, the average homography is defined as the homography that minimizes the average point shift from the original coordinates when points are mapped using, as reference, either the first or the second sub-mosaic.
-
F. Bellavia, M. Fanfani, F. Pazzaglia, C. Colombo, et al., "Piecewise planar underwater mosaicing", Oceans, 2015 | PDF
Compositional framework to analyse and design novel color correction methods for image stitching

Starting from the observation that any color correction method can be decomposed into two main computational units, we defined a new compositional framework for classifying color correction methods, which allowed us both to investigate existing methods from a new perspective, and to develop new and more effective solutions to the problem. The framework was used to dissect 15 among the best color correction algorithms. The computational units so derived, with the addition of 4 new units, were then reassembled in a combinatorial way to originate about one 100 distinct color correction methods, most of which never considered before. The above color correction methods were tested on three different existing datasets, including both real and artificial color transformations, plus a novel dataset of real image pairs categorized according to the kind of color alterations induced by specific acquisition setups. Comparative results show that combinations of the computational units newly designed for this work are the most effective for real stitching scenarios, regardless of the specific source of color alteration. This is achieved by employing monotone cubic splines to locally model the correction function, that also take into account the gradient of both the source and target images so as to preserve the image structure.
-
F. Bellavia and C. Colombo, "Color correction for image stitching by monotone cubic spline interpolation", IbPRIA, 2015 | PDF | Additional material | Slides
-
F. Bellavia, C. Colombo, "Dissecting and Reassembling Color Correction Algorithms for Image Stitching", 2018, to appear | PDF | Additional Material
Image mosaicing with high parallax scenes

An original image-based rendering approach based on fundamental matrices is here employed to obtain accurate image mosaics from scenes with high parallax (and then not suitable for the classical homography-based mosaicing techniques). In particular, visual information is transferred from an image to any other thanks to the epipolar propagation on the connected graph of fundamental matrices, while SIFT dense stereo matching is used to obtain the output mosaic. Additionally, epipolar relations are employed to correctly handling occlusions induced by the parallax.
-
A. Nardi, D. Comanducci, and C. Colombo, "Augmented vision: Seeing beyond field of view and occlusions via uncalibrated visual transfer from multiple viewpoints", IMVIP, 2011 (Best paper award) | PDF
Historical Stereo Photographs Restoration and Enhancement

A fully automatic approach to the digital restoration of historical stereo photographs is proposed. The approach exploits the content redundancy in stereo pairs for detecting and fixing scratches, dust, dirt spots and many other defects in the original images, as well as improving contrast and illumination. This is done by estimating the optical flow between the images, and using it to register one view onto the other both geometrically and photometrically. Restoration is then accomplished by data fusion according to the stacked median, followed by gradient adjustment and iterative visual consistency checking. The obtained output is fully consistent with the original content, thus improving over the methods based on image hallucination.
-
M. Fanfani, C. Colombo and F. Bellavia, "Restoration and enhancement of historical stereo photos", Journal of Imaging, MDPI 2021 | PDF | Add. Material - full size paper figures | Add. Material - evaluation results
Multi-image super-resolution of corneal endothelium
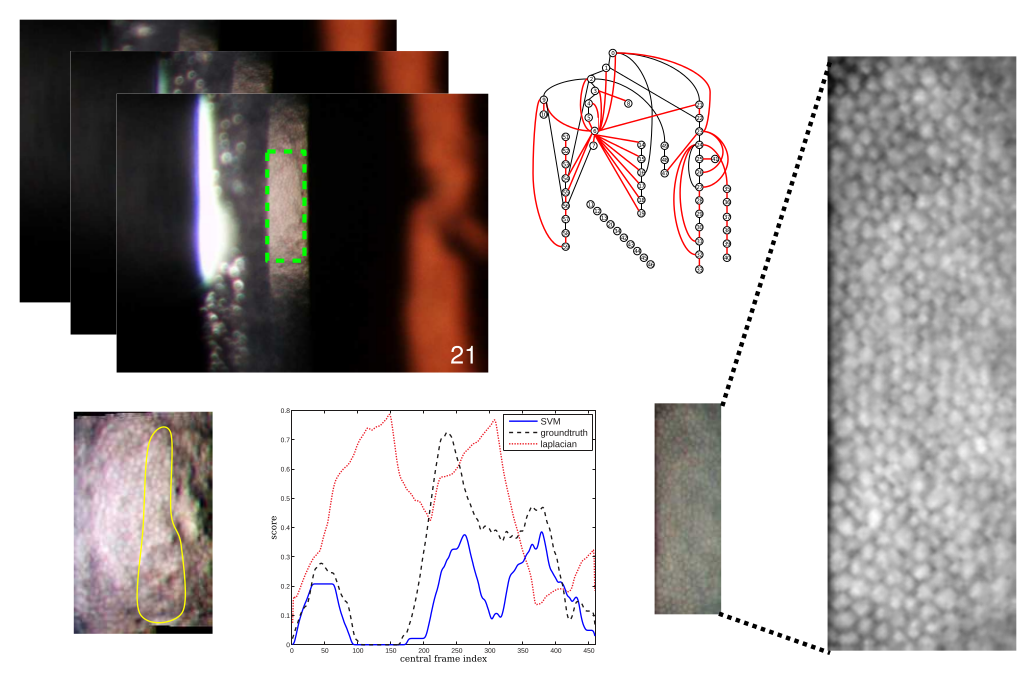
In collaboration with VISIA Imaging s.p.a., we developed a practical and effective method to compute a high-resolution image of the corneal endothelium starting from a low-resolution video sequence obtained with a general purpose slit lamp biomicroscope. This is obtained thanks to an SVM-based learning approach for identifying the most suitable endothelium video frames, followed by a robust graph-based mosaicing registration. An image quality typical of dedicated and more expensive confocal microscopes is obtained using only low-cost equipment, which makes the method valid and affordable as a diagnostic tool for medical practice in developing countries.
Image Forensics
Computer vision based image cropping detection
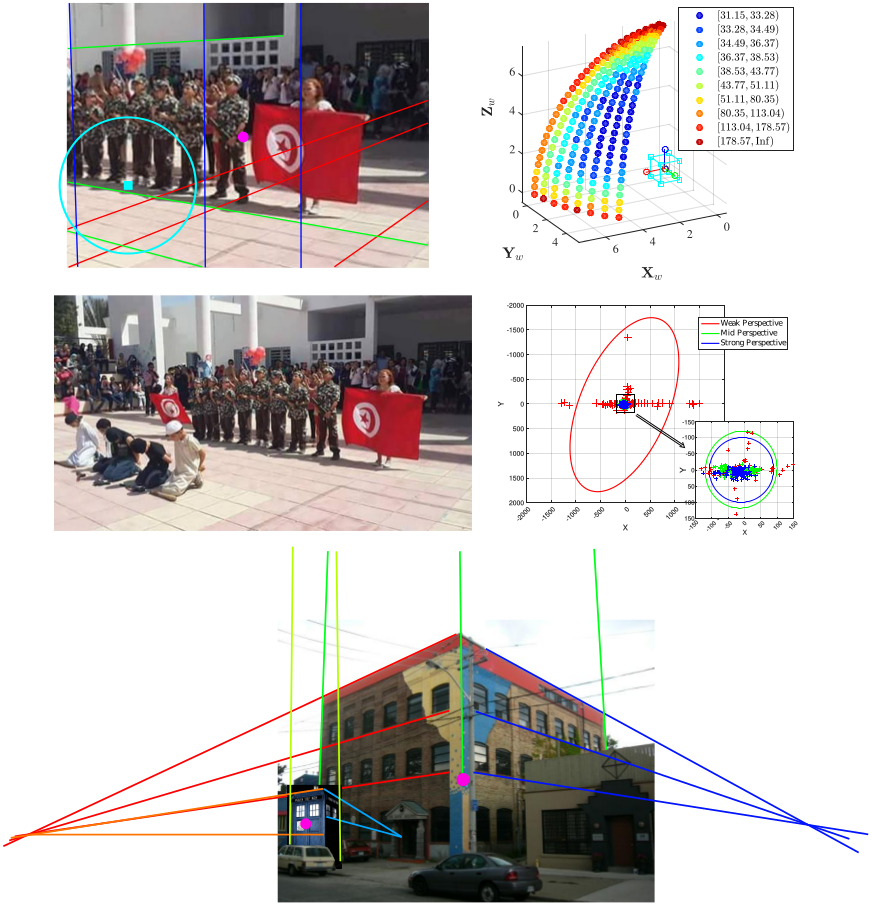
Principal Point (PP) estimation can be used in image forensic analysis to detect image manipulations such as asymmetric cropping or image splicing. ACID (Automatic Cropped Image Detector), is a fully automated detector for exposing evidences of asymmetrical image cropping. The proposed solution estimates and exploits the camera principal point, i.e., a physical feature extracted directly from the image content that is quite insensitive to image processing operations, such as compression and resizing, typical of social media platforms. Robust computer vision techniques are employed throughout, so as to cope with large sources of noise in the data and improve detection performance. The method leverages a novel metric based on robust statistics, and is also capable to decide autonomously whether the image at hand is tractable or not.
- M. Iuliani, M. Fanfani, C. Colombo and A. Piva, "Reliability Assessment of Principal Point Estimates for Forensic Applications", Journal of Visual Communication and Image Representation, 2016 | PDF
- M. Fanfani, M. Iuliani, F. Bellavia, C. Colombo and A. Piva, "A vision-based fully automated approach to robust image cropping detection". Signal Processing: Image Communication, Elsevier, 2019 | PDF
Face splicing detection with lighting-based feature
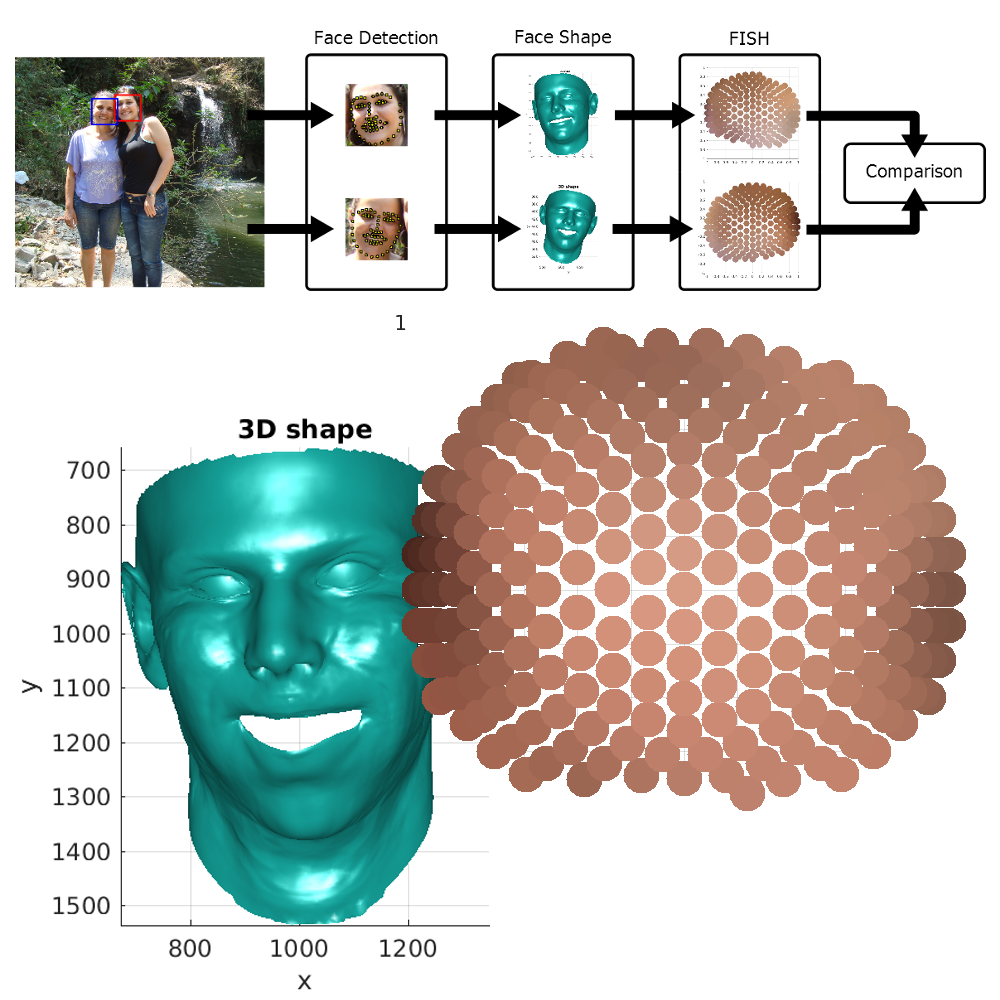
Face splicing manipulations, where recognizable identities are put out of context, spread nowadays over any visual media influencing our judgement. We present a novel method for automatic face splicing detection, based on computer vision, that exploits inconsistencies in the lighting environment estimated from different faces in the scene. Differently from previous approaches, we do not rely on an ideal mathematical model of the lighting environment, but we propose instead to measure discrepancies on histograms that statistically model the interaction of faces with light.
- M. Fanfani, F. Bellavia, M. Iuliani, A. Piva and C. Colombo, "FISH: Face Intensity-Shape Histogram representation for automatic face splicing detection", Journal of Visual Communication and Image Representation, 2019 | PDF | Source code
PRNU registration based on convolutional neural networks
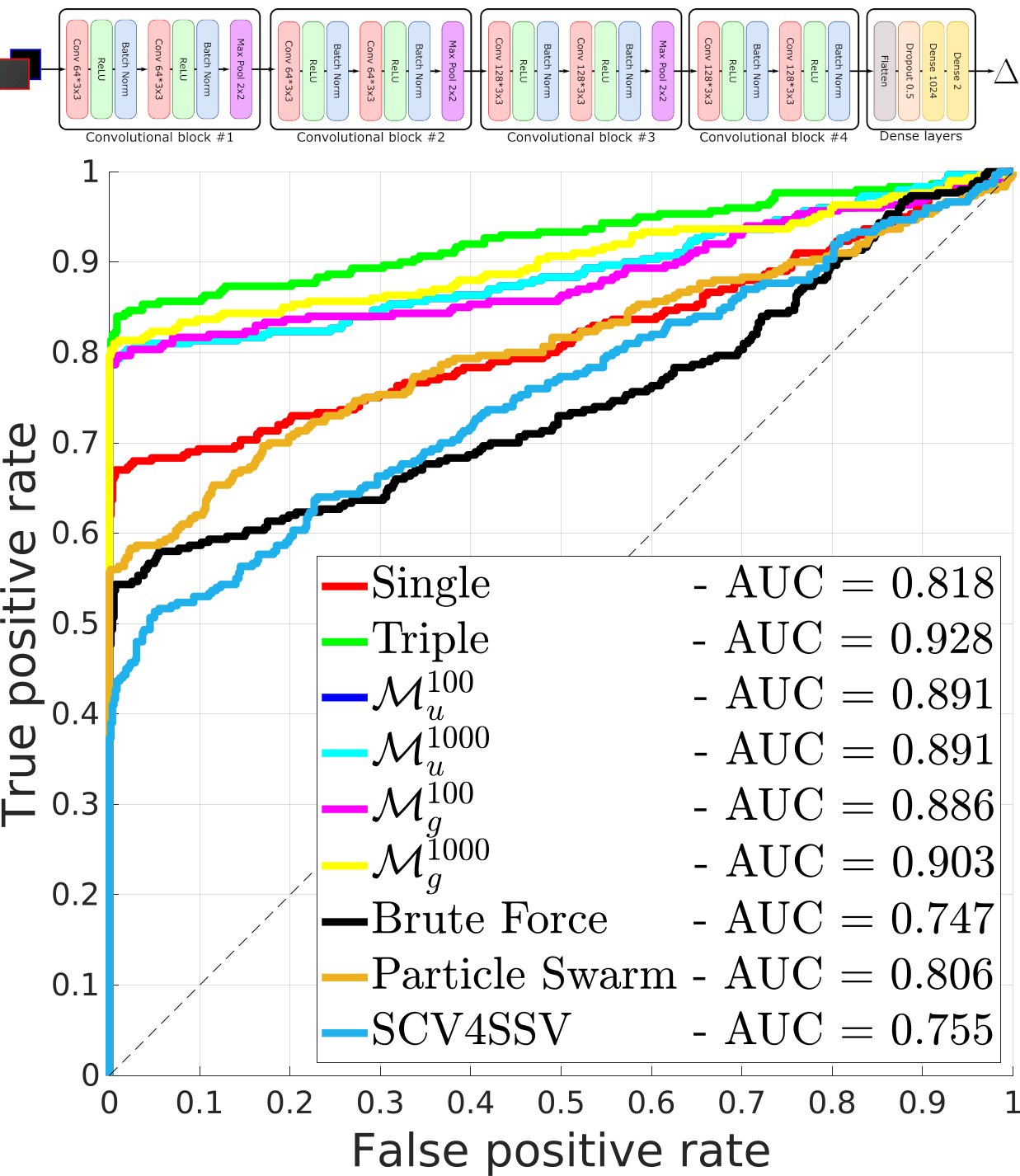
We studied the Photo Response Non Uniformity (PRNU) pattern matching, a delicate task that requires pixel level accuracy. Even slight geometric image transformations can misalign the residual noise of the probe and the fingerprint, thus spoiling the camera identification task. While image translations can easily be recovered as a by-product of PCE computation, scale and rotation transformations introduce a higher degree of complexity, since they have to be explicitly recovered before evaluating any correlations. To provide a fast and accurate solution, we present a method based on deep learning to recover scale and rotation transformations between PRNU signals. This method can be used as a fast pre-processing step before evaluating the PCE.
-
M. Fanfani, A. Piva and C. Colombo, "PRNU registration under scale and rotation transform based on Convolutional Neural Networks", Pattern Recognition, 2022 | PDF
PRNU pattern alignment for images and videos based on scene content

A novel approach for registering the PRNU pattern between different acquisition modes is presented. This method relies on the imaged scene content: image registration is achieved by establishing correspondences between local descriptors; the result can optionally be refined by maximizing the PRNU correlation. The proposed scene-based approach for PRNU pattern alignment is suitable for video source identification in multimedia forensics applications. Furthermore, a tracking system able to revert back EIS in controlled environments is designed. This allows one to investigate the differences between the existing EIS implementations.
-
F. Bellavia, M. Iuliani, M. Fanfani, C. Colombo and A. Piva, "PRNU pattern alignment for images and videos based on scene content", ICIP, 2019 | PDF | Source code | Dataset
-
F. Bellavia, M. Fanfani, A. Piva and C. Colombo, "Experiencing with electronic image stabilization and PRNU through scene content image registration", Pattern Recognition Letters, 2021 | PDF | Alignment code and data | Tracker code and data
Statistically accurate measurements from a single image

Geometric methods of computer vision has been applied to extract accurate measurements from video frames in a sport justice case on an international bridge tournament. In particular, calibration parameters were extracted from the card table and sub-pixel edge detection of the cards were employed to obtain very accurate measurements.
Aids for Visually Impaired People
Obstacle detection on smartphones

An effective obstacle detection application running on smartphones was developed to help visually impaired people. The system uses a SfM approach, modified to use more reliable position information by exploiting the phone gyroscope data. A robust RANSAC-based approach is used on the estimated 3D structure to detect the principal plane and localize out-of-plane objects to be marked as obstacles.
BusAlarm: bus line number detection

BusAlarm is a smartphone application that automatically reads the bus line number, assisting visually impaired people in taking public transport and improving their autonomy in daily activities. BusAlarm combines machine learning with geometric and template matching_approaches and OCR techniques to correctly detect the incoming bus, find the line number location and output the final answer to the user.